Architecture and Infrastructure#
Cluster Tier Architecture#
The figure below outlines a first version for cluster tiers and their interplay (see also issue #43) . A cluster tier is defined as a well-defined set of services (incl. the corresponding software-stack) that must run in the same cluster / a set of virtual machines. A cluster tier comes with an installation procedure, a software stack and hardware/cluster requirements and has a responsible operator.
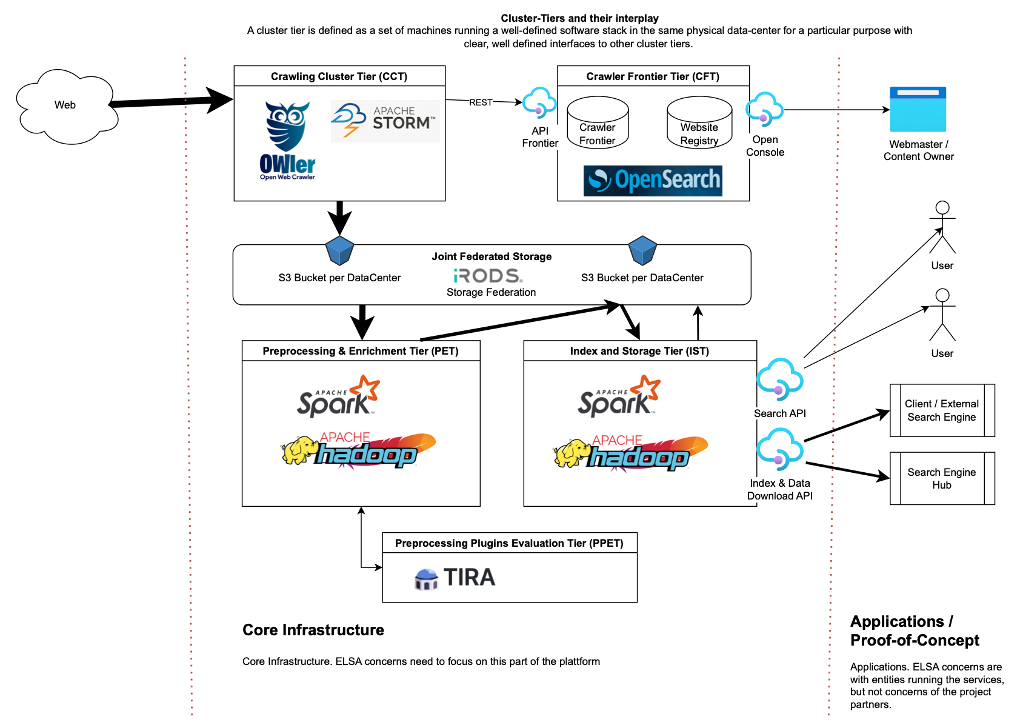
Currently we have foreseen four cluster tiers:
Crawling Cluster Tier (CCT) contains a crawler responsible for crawling the web thereby creating WARC-files (i.e. collection of HTTP streams from the crawling process). WARC Files are stored in an S3 Bucket which can be accessed by the other tiers. There can be multiple CCT, but there should be only one CCT per data center, as the CCT can scale with the amount of resources provided.
Crawler Frontier Tier (CFT) will be a singleton tier (i.e. there is only one instance across all participating data centers) coordinating the crawls. It stores crawled urls including access statistics and cache digest. From the crawler frontier we will derive the website registry and provide an interface for the interaction from webmasters with the frontier (e.g. an interface for take-down requests).
Preprocessing and Enrichment Tier (PET) takes the WARC files from the S3 Bucket filled by the CCT and extracts cleaned HTML as well as further metadata. Following the partitioning of the CCT, each data center should have a dedicated PET for the WARC files stored at that data center. The metadata extracted by the PET will be stored in Parquet format. Responsible WP: WP 2
Index and Storage Tier (IST) turns the cleaned content from the PET into 1) a usable index/inverted file, and 2) a web graph (including anchor texts). Similar to the CCT, each data center should have its own IST (and only one), responsible for creating an index for the documents crawled by that data center. The ISTs of each data center might need to communicate (parts of) the web graph to each other, to account for hyperlinks between pages crawled by different data centers. The inverted files will be partitioned by certain types of metadata, such as topic, language, TLD, etc. Aside from the inverted file and web graph, the IST will also contain a metadata store in Parquet format. The inverted files, web graphs and metadata stores can be downloaded through an API. The API provides filtering options, to allow third parties to download only those parts of the index that are relevant to their use cases. The inverted files are distributed as CIFF files, the web graphs and metadata stores as Parquet files.
Preprocessing Plugins Evaluation Tier (PPET) enables the evaluation of plugins to the content analysis library. In order to expand enrichment capabilities, both project members as well as third parties may develop plugins used in the PET. To ensure good quality and sufficient throughput, candidate plugins will perform their enrichment task on benchmarking data. This evaluation will be performed using the TIRA platform hosted at a data center.
Federated Data Storage#
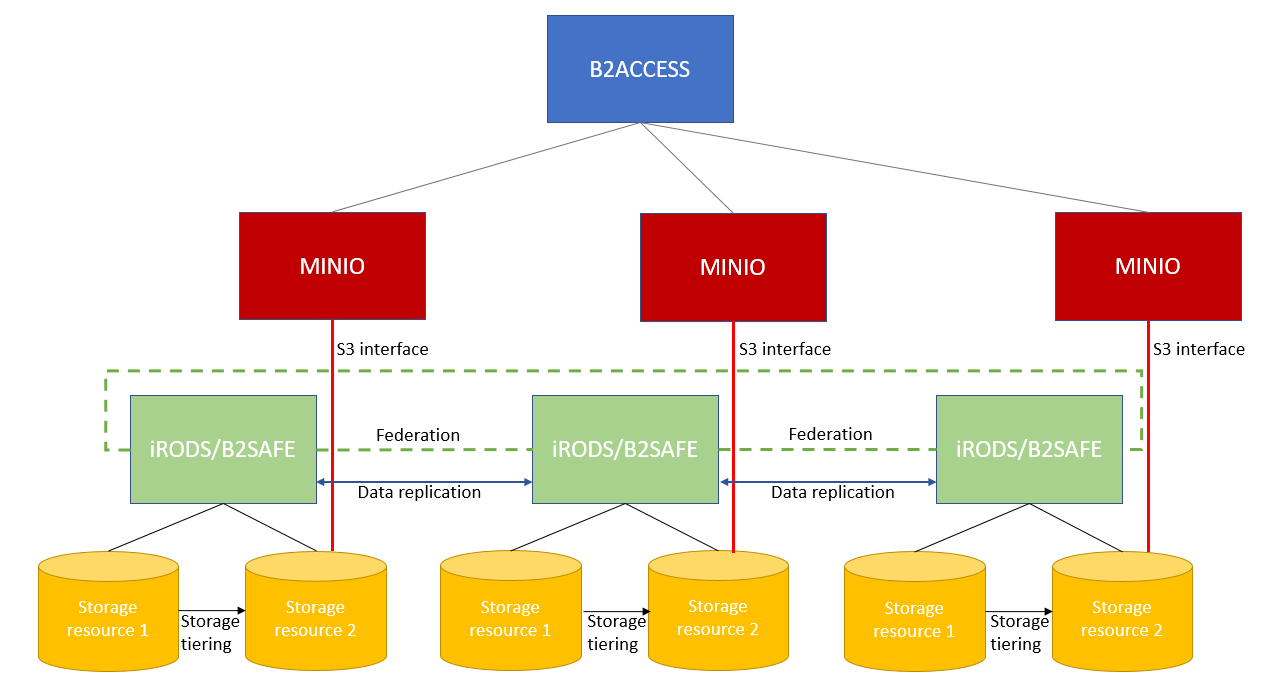
The data infrastructure exposes a file hierarchy / object hierarchy. Data written to iRODS will be federated across the data centers. MinIO will be the S3 compliant access protocol with one bucket per data center. The bucket will access the iRODS data folder of that particular zone.
Data exchange between individual tiers is organised according to an agreed folder structure. Zonenames/bucket-names form the root entry and specify the access location and guide data-locality. If the tier does not run in the same zone, data access can be cost intensive.
Below are specifications examples for the folder hierarchy (path-on-system). Replication needs to be specified on a per-folder basis.
Example Folder Structure#
> mc du -r -d 3 owseu-lrz/lrz/
3.0GiB 683 objects lrz/index/2023-05
38GiB 3156 objects lrz/index/2023-06
60GiB 4302 objects lrz/index/2023-07
102GiB 8141 objects lrz/index
543GiB 32751 objects lrz/preprocessed/2023-09
4.5GiB 554 objects lrz/preprocessed/2023-10
32MiB 121 objects lrz/preprocessed/log
547GiB 33426 objects lrz/preprocessed
16GiB 69 objects lrz/spark-logs
162GiB 1661 objects lrz/warc/2023-08
3.1TiB 33188 objects lrz/warc/2023-09
553GiB 6019 objects lrz/warc/2023-10
3.8TiB 40868 objects lrz/warc
4.5TiB 82509 objects lrz
Folder Structure Specification#
bucket-name/ # zone to enable fast access to data for all tiers in the zone
warc/ # folder containing ALL WARC files crawled
YYYY-MM/ # folder with WARC files crawled in year YYYY and month MM
DD/ # WARC files for day DD.
{_crawler_name_}/ # Name of the crawler
HHmmss-{int}.warc.gz # single warc file. Namen scheme subject to change
preprocessed/ # folder containing output from preprocessing based access.
YYYY-MM/ # folder with preprocessing data in year YYYY and month MM
DD/ # daily batch of results.
Date-{class}-{split}.parquet # main result of preprocessing. naming scheme to be defined
Date-{class}-{split}.log.gz # zipped log file for written parquet files (when + stats)
index/ # folder containing output from indexing (i.e. CIFF files)
YYYY-MM/ # folder with preprocessing data in year YYYY and month MM
DD/ # sub-daily batch of results.
{TLD}/{LANG}/ # Index partitioning scheme. Subject to change based on experiments
index-{num?}.ciff # main result of indexing. naming scheme to be defined.
metadata-{num?}.parquet # main result of indexing/preprocessing. naming scheme to be defined.
Other File Structures:#
shared/
auxiliary/ # auxiliary data which is replicated among all nodes
models/ # machine learning models, preprocessing models
plugins/ # plugins for preprocessing to be shared
filters/ # data for filters to be shared.
logs.csv # log file of updates. Potentially useful for notification
on_demand/ # folder for on demand data crawling / indexing requests This is data which is not
uuid-on-demand/ # folder with configuration files of a specific on demand request
config.json # json file with the configuration except for the urls
url_patterns.txt # patterns of urls to be provided
public/ # folder containing public files (e.g. downloads)
[ABCDEF]/ # probably provision of sub-indices or delta updates with a
community/ # folder for communities and third parties doing their own
# processing / computing. This can be either interested third
# parties or third parties funded by us.
[ABCDEF]/ # one folder per community / third party
Crawling data will be preprocessed on a daily basis, i.e. the crawler guarantees to write WARCs on a daily basis. Nevertheless, the crawler cannot guarantee it on the second, so
DD/directories should be only preprocessed after a certain amount of time (e.g. 2 hours afterDD+1).Preprocessing results will be written to the file in batches, potentially on a sub-daily basis, i.e. the preprocessor converts the daily WARCs and puts them into a directory for that day.